Das Schweizer Lernerkorpus SWIKO
Das Schweizer Lernerkorpus SWIKO wird im Rahmen der Forschungsprojekte SWIKO und WETLAND Forschungsprojekte am Institut für Mehrsprachigkeit in Freiburg (CH) erstellt. Derzeit enthält das Korpus über 2600 annotierte Texte mit mehr als 170 000 Token. Diese basieren auf mündlichen und schriftlichen Beiträgen von Schweizer Schülerinnen und Schülern der Sekundarstufe I in den Unterrichts- und Fremdsprachen Deutsch, Französisch und Englisch.
Diese Website bietet Informationen zum Projekt, insbesondere zur Erhebung und Verarbeitung der Daten, die aus verschiedenen projektinternen Dokumenten stammen. Ausserdem werden einige Nutzungsmöglichkeiten für den Unterricht, die Materialgestaltung und die Forschung vorgeschlagen.
Die Online-Korpusdatenbank ist derzeit über ein personalisiertes Login zugänglich, welches über direkt über SWIKOweb beantragt werden kann.
Korpusdesign
Nutzungsmöglichkeiten
Kontext und Ziele
SWIKO ist ein mehrsprachiges Parallelkorpus, das während zwei Forschungsperioden am Institut für Mehrsprachigkeit in Freiburg (Schweiz) erstellt wurde. Das Projekt untersucht ausgewählte Bereiche der Sprachkompetenz von Schweizer Sprachlernenden der Sekundarstufe I. Die Projektidee geht auf eine Veränderung im Fremdsprachenunterricht zurück: Um die Jahrhundertwende kam es zu einem Wechsel hin zu einem kompetenzbasierten sowie handlungs-, inhalts- und aufgabenorientierten Unterricht (Europarat, 2001). Die Schweiz lancierte in dieser Zeit auch das Projekt HarmoS, mit dem in den meisten Kantonen der Fremdsprachenunterricht an öffentlichen Schulen vereinheitlicht wurde (z. B. Lehrplan 21, D-EDK, 2023; oder New World, Arnet-Clark et al., 2013). In der Grundschule wurden Englisch und eine Landessprache als zwei Fremdsprachen obligatorisch, die erste ab der 3. Primarstufe, die zweite ab der 5. Primarstufe. So beginnen zum Beispiel in der französischsprachigen Schweiz die Schülerinnen und Schüler im Alter von 8 Jahren mit dem Deutschunterricht und im Alter von 10 Jahren mit dem Englischunterricht. Am Ende der obligatorischen 11-jährigen Schulzeit – im Alter von 15 Jahren – wird von den Jugendlichen erwartet, dass sie das Gesamtniveau A2.2 und schriftlich das Niveau A2.1 erreichen. Diese Vorgaben gelten für beide Fremdsprachen.
Aus einer ersten nationalen Erhebung (ÜGK, 2019) und ähnlichen Projekten (z. B. Peyer et al., 2016) wissen wir, dass die Lernenden die Standards teilweise erreichen, es aber erhebliche Unterschiede zwischen den Sprachen und Kompetenzen gibt. Über konkrete Sprachkompetenzen wissen wir jedoch viel weniger. Daher ist es das Hauptanliegen von SWIKO, die Interimssprache der Lernenden am Ende der obligatorischen Schulzeit empirisch zu dokumentieren und zu analysieren – unter Berücksichtigung des oben genannten Paradigmenwechsels und insbesondere in Bezug auf Lexik und Grammatik.
Ausgehend vom handlungsorientierten Unterricht sind die Schülerproduktionen im SWIKO-Korpus aufgabenorientiert. Ein besonderes Augenmerk liegt auf dem Zusammenwirken verschiedener produktionsrelevanter Bedingungen wie der Sprache (Deutsch, Französisch und Englisch als Unterrichtssprache (US) und Fremdsprache (FS)), der Modalität (schriftliche vs. mündliche Produktion) und des Mediums (Computer vs. Papier) sowie auf den Merkmalen der Aufgabengestaltung wie Textart (beschreibend vs. argumentativ), Themenvertrautheit (akademisch vs. persönlich) und Struktur (mehr oder weniger restriktiver Input). So kann untersucht werden, wie sich Veränderungen dieser Variablen auf die Qualität einer Lernerproduktion auswirken.
Unser dreisprachiges Parallelkorpus ergänzt zahlreiche bereits vorhandene Korpora, indem es auf den öffentlichen Schulkontext, auf Lernende mit geringen Vorkenntnissen und auf mehrere Sprachen sowohl als Unterrichts- als auch als Fremdsprache ausgerichtet ist.
Aktueller Umfang
Bis Ende 2024 wurden Daten aus drei verschiedenen Lehrplanregionen gesammelt und in den folgenden Teil-Korpora erfasst:
- SWIKO17 (Westschweiz, Deutsch 1. FS, English 2. FS)
- SWIKO18 (Deutschschweiz, Französisch 1. FS, Englisch 2. FS)
- SWIKO19 (Deutschschweiz, Deutsch und Englisch als US)
- SWIKO22 (Westschweiz, Deutsch 1. FS, Englisch 2. FS).
Da die Teilnehmenden die Aufgaben sowohl in ihrer Unterrichtssprache (US) als auch in ihrer Fremdsprache (FS) erledigten, entstand ein dreisprachiges (Deutsch, Englisch und Französisch) Lernerkorpus.
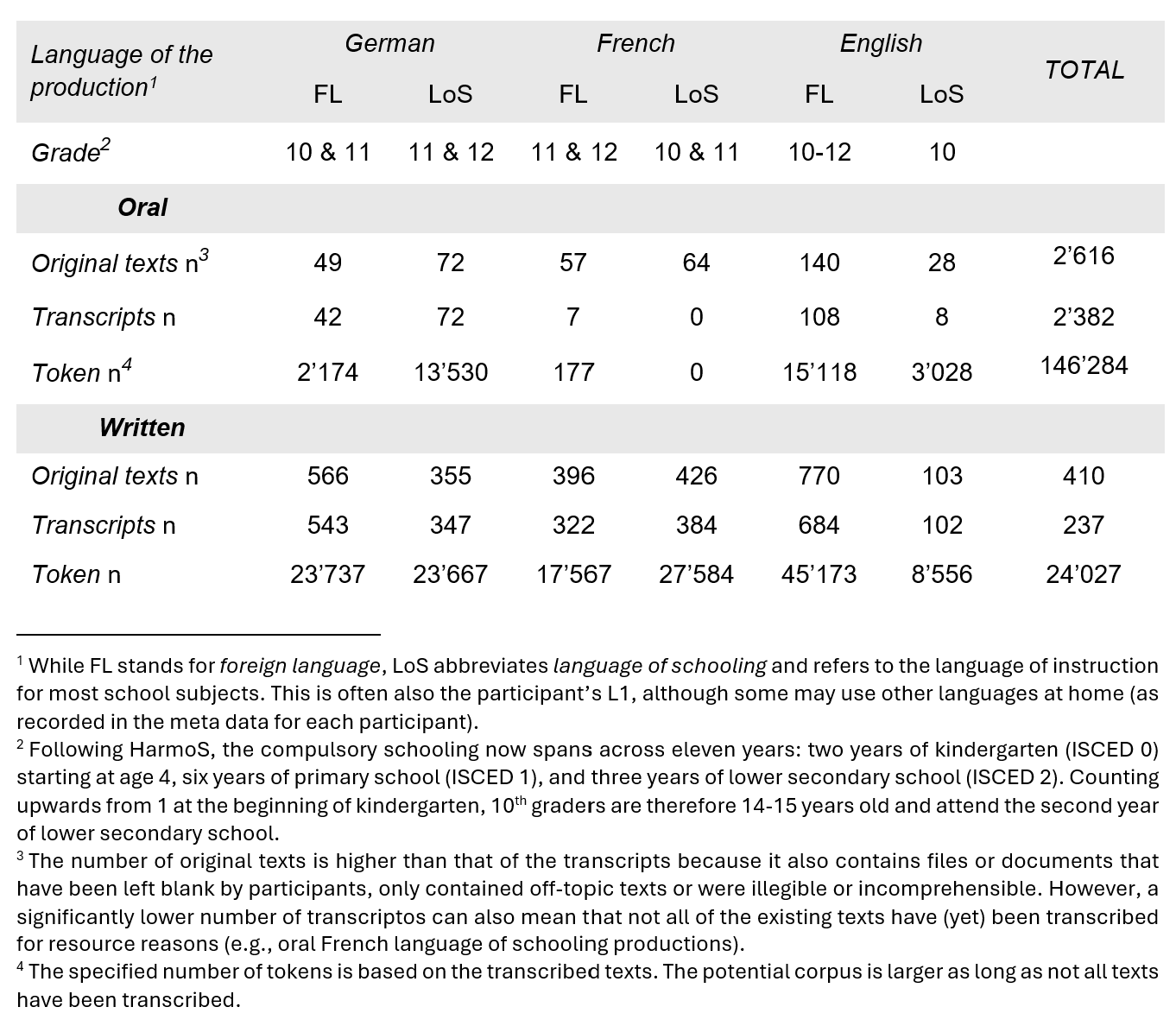
Datenerhebung und Aufgabenvariation[Zurück]
Um die Bandbreite der Aufgaben im Fremdsprachenunterricht abzubilden, wurden acht Aufgaben erstellt und systematisch anhand von drei Merkmalen variiert: Textart, Themenkenntnis und Struktur. Die Schülerinnen und Schüler bearbeiteten die Aufgaben unter verschiedenen Bedingungen: in drei Sprachen (sowohl in ihrer Unterrichtssprache als auch in Fremdsprachen) sowie mit zwei verschiedenen Medien und in zwei verschiedenen Modalitäten.
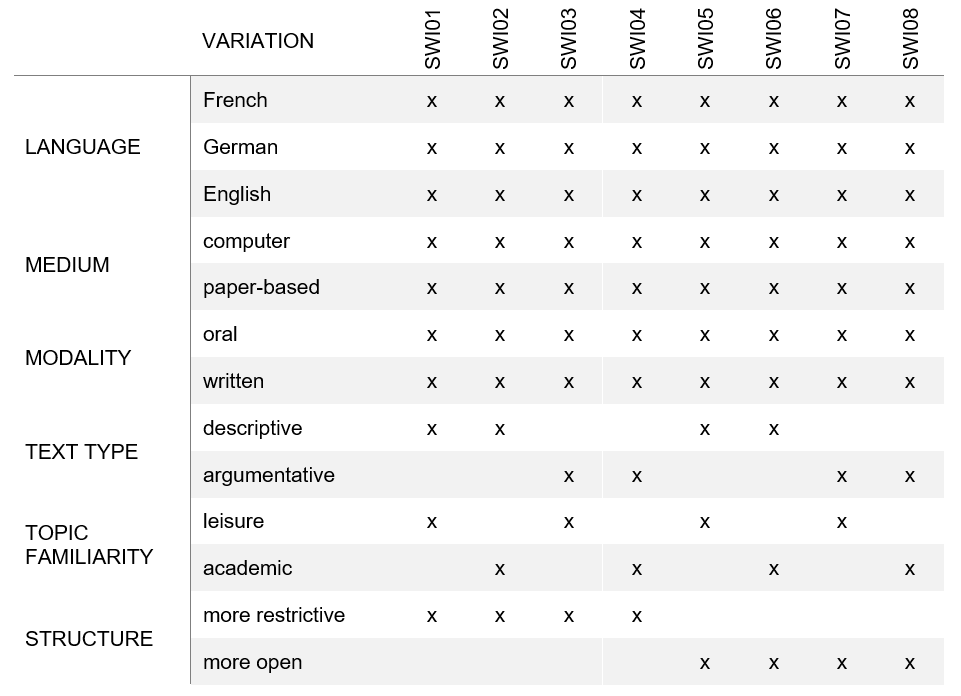
Die komplementären Aufgaben SWI04 und SWI05 veranschaulichen die Variation der Aufgabenmerkmale und Produktionsbedingungen in SWIKO:
Bei der Aufgabe SWI04 mussten die Lernenden eine Liste der 100 wichtigsten Erfindungen diskutieren. Im Beispiel wurde die Aufgabe Lernenden mit Deutsch als Unterrichtssprache gestellt, wobei sie in ihrer Fremdsprache Französisch antworten sollen. Das Ergebnis ist ein schriftlicher Text auf Papier mit den Merkmalen argumentativ, zu einem akademischen Thema und mit einer restriktiven Struktur.

Bei der Aufgabe 5 wurden die Lernenden dagegen gebeten, ein Selbstporträt für einen Klassenaustausch zu schreiben. Die Aufgabe wurde Lernenden mit Französisch als Unterrichtssprache gestellt, wobei sie eine mündliche, computerbasierte Antwort in ihrer Fremdsprache Deutsch geben sollten. Die Aufgabe weist die Merkmale deskriptiv, zu einem persönlichen Thema und mit weniger Struktur auf.
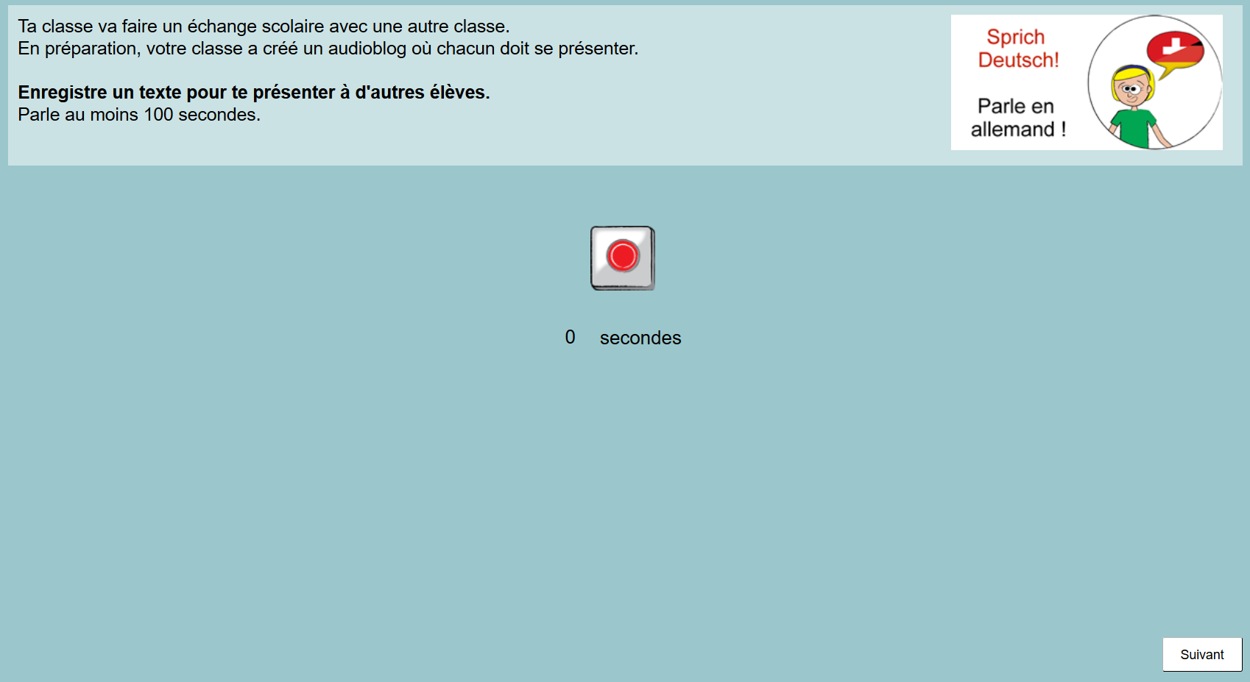
Die Daten wurden zwischen 2017 und 2022 von 14- bis 17-jährigen Schülerinnen und Schülern der 10. bis 12. Klasse in drei Schweizer Regionen erhoben: in neun Westschweizer Klassen mit Deutsch als erster und Englisch als zweiter Fremdsprache, in sechs Deutschschweizer Klassen mit Französisch als erster und Englisch als zweiter Fremdsprache und in einer Deutschschweizer Klasse mit Englisch und Deutsch als Unterrichtssprache. Die Schülerinnen und Schüler arbeiteten während des regulären Unterrichts zweimal 45 Minuten an den Aufgaben.
Aufgabenvariation
Die acht Aufgaben basierten weitgehend auf dem TBLT-Rahmen (Task-Based Language Teaching, z. B. Ellis et al. 2020; Long, 2015) und variierten hinsichtlich dreier Merkmale:
Textart (oder rhetorischer Modus in Ellis et al. 2020, oder linguistische Makrofunktion in GER, 2001 oder Textgenre in CIIP, 2010), entweder als deskriptiv oder als argumentativ charakterisiert;
Themenvertrautheit (BLC und HLC, Hulstijn, 2015), entweder als persönlich oder als akademisch charakterisiert;
Struktur (Samuda & Bygate, 2008), entweder restriktiv oder offen charakterisiert.
Die systematische Variation dieser drei Merkmale führte bei jeder der acht Aufgaben zu einer anderen Kombination. Die Aufforderungen lauteten wie folgt:
SWI01: Beantworte kurze persönliche Fragen
SWI02: Beschreibe Grafiken über Haustiere in der Schweiz
SWI03: Diskutiere eine Liste mit Ferienmöglichkeiten
SWI04: Diskutiere eine Liste mit den wichtigsten Erfindungen
SWI05: Erstelle ein Selbstporträt für einen Klassenaustausch
SWI06: Präsentiere ein Thema (aus acht vorgegebenen Vorschlägen)
SWI07: Diskutiere die Frage, ob die Schule später beginnen und enden sollte
SWI08: Diskutiere die Frage, ob der Fremdsprachenunterricht durch einen Sprachaustausch im Ausland ersetzt werden sollte.
Produktionsbedingungen: Sprache, Medium und Modalität
Die Produktionen wurden unter drei Bedingungen erstellt:
drei Sprachen (Deutsch, Englisch und Französisch), je nach Ort der Datenerhebung als Unterrichtssprache (L1 für die meisten Schülerinnen und Schüler) und als Fremdsprache; alle Teilnehmenden erledigten jeweils vier Aufgaben in zwei der drei Sprachen;
schriftlicher und mündlicher Modus
auf Computer und auf Papier (Medium)
Alle Aufgaben wurden sowohl als computerbasierte Version mit der Software CBA Item Builder (DIPF & Nagarro, 2018b) als auch als identische, papierbasierte (d. h. nicht computergestützte) Version entwickelt. Um Missverständnisse zu vermeiden, wurden die Anweisungen immer in der Unterrichtssprache vorgelegt (Barras et al., 2016; Karges et al., 2021). Bei den Aufgaben im schriftlichen Modus wurde in einem Feld die Anzahl zu schreibende Wörter angegeben. Beim gesprochenen, computergestützten Modus konnten die Teilnehmenden ihre Aufnahme durch das Anklicken einer roten Taste steuern. Sie wurden angewiesen, mindestens 100 Sekunden lang zu sprechen, am Ende waren aber die meisten Aufnahmen kürzer.
Datenverarbeitung[Zurück]
Nach der Datenerhebung wurden die Originaltexte der Lernenden so originalgetreu wie möglich transkribiert und für das Part-of-speech-Tagging (POS-Tagging) manuell annotiert. Anschliessend wurden sie mit TreeTagger tokenisiert, lemmatisiert und mit POS-Tags versehen. Dabei wurden sowohl sprachspezifische Tags aus dem koRpus Package als auch allgemeine POS-Tags verwendet, die erstellt wurden, um einen Vergleich der Produktionen in allen drei Sprachen zu ermöglichen. Schliesslich wurden sie in EXMARaLDA importiert. Dabei wurden alle schriftlichen deutschen Produktionen zusätzlich um eine Zielhypothese und halbautomatische Fehlerannotation ergänzt.
In einem nächsten Schritt wurden alle schriftlichen Produktionen von geschulten Bewertenden anhand der vier linguistischen Kriterien Wortschatz, Grammatik, Rechtschreibung und Text sowie unter Verwendung von GER-Deskriptoren bewertet. Die Bewertungen wurden anschliessend mit einer Multifacetten-Rasch-Analyse ausgewertet, um eine faire und konsistente Bewertung sicherzustellen. Ein Beispiel eines schriftlichen Texts ist unten aufgeführt.

Transkription und erste Kennzeichnung
Alle Produktionen wurden zweimal transkribiert: einmal so originalgetreu wie möglich und einmal mit Kennzeichnungen, um sie für die automatische Annotation im nächsten Schritt vorzubereiten. So wurden beispielsweise Rechtschreibfehler korrigiert und nicht-zielsprachliche Wörter übersetzt, wobei stets sowohl die Originalversion als auch die korrigierte Version erfasst wurde. Die Transkriptions- und Annotationsrichtlinien basieren auf einem XML-Skript, das freundlicherweise vom MERLIN Projektteam zur Verfügung gestellt wurde. Die schriftlichen Produktionen wurden in XMLmind (Shafie, 2021) transkribiert. Für die mündlichen Daten wurde der EXMaRALDA Partitur-Editor (Schmidt & Wörner, 2009) verwendet, die Richtlinie wurde anhand eines Vergleichs mehrerer Transkriptionssysteme (z. B. GAT 2; Selting et al. 2009) entwickelt.
Download Transkriptionsrichtlinien für schriftliche Produktionen
Download Transkriptionsrichtlinien mündliche Produktionen
Download Richtlinien für erste Kennzeichnungen
Annotation
In einem nächsten Schritt wurden die Transkriptionen mit speziell entwickelten R-Skripten (R Core Team, 2022) in CSV-Dateien im Verzeichnis ./homepages umgewandelt und mit TreeTagger (Schmid, 2013) und dem koRpus Package (Michalke, 2019) tokenisiert, lemmatisiert und mit POS-Tags versehen. Wir haben sowohl die sprachspezifischen POS-Tags (z. B. STTS für Deutsch) einbezogen als auch einen gemeinsamen POS-Tag für alle drei Sprachen festgelegt. Bei allen schriftlichen deutschen Produktionen wurde für jeden Lernertext eine Zielhypothese – eine orthografisch und grammatikalisch korrekte Version (Lüdeling & Hirschmann, 2015) – definiert, die als Grundlage für eine halbautomatische Fehlerannotation diente. Ausserdem wurden in allen mündlichen deutschen Texten manuell die Fehler annotiert.
Download Richtlinie zur Formulierung der Zielhypthesen
Download Erklärung der Fehlerannotation mit Beispielen
Rating
Alle fremdsprachlichen Lernertexte wurden anhand der Deskriptoren von Lingualevel (Lenz & Studer, 2008) und dem GER Begleitband (Europarat, 2020) mit den Niveaus Pre-A1 bis B2+ bewertet. Die Bewertenden mussten zwei Trainingsmodule absolvieren. Sie bewerteten die Produktionen anhand des folgenden Bewertungsrasters nach den vier Analysekriterien Wortschatz, Grammatik, Rechtschreibung und Text.
Download Bewertungsraster
Anschliessend wurde eine Multifacetten-Rasch-Analyse (Eckes, 2015; Linacre, 1994) unter Verwendung von FACETS (Linacre, 2022) mit einer 3-Facetten-Analyse (Texte x Bewertende x 4 Kriterien) pro Sprache durchgeführt, um eine faire Bewertung für jede Produktion zu erhalten. Vier Bewertende (R09, R18, R20 und R22) für die deutschen Produktionen wurden aufgrund unbefriedigender Infit- und Outfit-Masse durchgehend ausgeschlossen. Zudem ergab ein Vergleich der Bewertungsstrenge zwischen den Sprachen, dass die deutschen Bewertenden insgesamt weniger streng waren. Aus diesem Grund wurden die Bewertungen aller deutschen Texte um −0,05 gesenkt (zum Beispiel von 5,19 auf 5,14).
Download MFRM-Output Deutsch als Fremdsprache
Download MFRM-Output Englisch als Fremdsprache
Download MFRM-Output Französisch als Fremdsprache
Artikel und Buchkapitel
Hicks, N. S. & Studer, T. (2024). Language corpus research meets foreign language education: examples from the multilingual SWIKO corpus. Babylonia Multilingual Journal of Language Education, 2,26-35
Download Arbeitsblätter Negation im DaF-Unterricht
Studer, T. & Hicks, N. S. (i.V.). Zugang zu und Umgang mit fremdsprachlichen Lernertexten unter den Vorzeichen schulisch intendierter Mehrsprachigkeit: Befunde und Herausforderungen am Beispiel des Schweizer Lernerkorpus SWIKO. Book chapter in Schmelter, L. (ed.).
Karges, K., Studer, T., & Hicks, N. S. (2022). Lernersprache, Aufgabe und Modalität: Beobachtungen zu Texten aus dem Schweizer Lernerkorpus SWIKO. Zeitschrift für germanistische Linguistik, 50(1), 104–130.
Karges, K., Studer, T., & Wiedenkeller, E. (2020). Textmerkmale als Indikatoren von Schreibkompetenz. Bulletin suisse de linguistique appliquée, No spécial Printemps 2020, 117–140.
Karges, K., Studer, T., & Wiedenkeller, E. (2019). On the way to a new multilingual learner corpus of foreign language learning in school: Observations about task variation. In A. Abel, A. Glaznieks, V. Lyding, & L. Nicolas (Hrsg.), Widening the Scope of Learner Corpus Research. Selected papers from the fourth Learner Corpus Research Conference (pp. 137–165). Presses universitaires de Louvain.
Vorträge
Studer, T. & Hicks, N. S. (2024). Korpora konkret: Nutzung eines mehrsprachige Lernerkorpus im schulischen DaF-Unterricht [presentation]. RPFLC, Fribourg.
Hicks, N. S. & Studer, T. (2024). «Da muss einfach mehr Fleisch an den Knochen» - Ein Gespräch über den Nutzen des Lernerkorpus SWIKO für den Fremdsprachenunterricht [Interview]. CEDILE.
Hicks, N. S. (2023). Lexical features in adolescents’ writing: Insights from the trilingual parallel corpus SWIKO [presentation]. Workshop on Profiling second language vocabulary and grammar, University of Gothenburg.
Liste Lamas, E., Runte, M, & Hicks, N. S. (2023). Datenbasiertes Lehren und Lernen mit Korpora im Fremdsprachenunterricht [workshop]. Internationale Delegiertenkonferenz IDK, Winterthur.
Studer, T. & Hicks, N. S. (2022). The interplay of task variables, linguistic measures, and human ratings: Insights from the multilingual learner corpus SWIKO [presentation]. European Second Language Acquisition Conference, Fribourg.
Weiss, Z., Hicks, N. S., Meurers, D., & Studer, T. (2022). Using linguistic complexity to probe into genre differences? Insights from the multilingual SWIKO learner corpus [presentation]. Learner Corpus Research Conference, Padua.
Studer, T., Karges, K., & Wiedenkeller, E. (2019). Machen Tasks den Unterschied? Ein korpuslinguistischer Zugang zur Qualität von Lernertexten in den beiden Fremdsprachen der obligatorischen Schule [presentation]. Studientag VALS-ASLA: Mehrschriftlichkeit im Fremdsprachenerwerb, Brugg.
Karges, K., Wiedenkeller, E., & Studer, T. (2018). Task effects in the assessment of productive skills – a corpus-linguistic approach [poster]. 15th EALTA conference, Bochum.
Unterricht und Materialgestaltung[Zurück]
Der folgende Artikel zeigt am Beispiel der Negation im Deutschen, wie SWIKO zur Erstellung von Unterrichtsmaterialien für den DaF-Unterricht auf Sekundarstufe I eingesetzt werden kann.
Hicks, N. S. & Studer, T. (2024). Language corpus research meets foreign language education: examples from the multilingual SWIKO corpus. Babylonia Multilingual Journal of Language Education, 2,26-35
Download Arbeitsblätter Negation im DaF-Unterricht
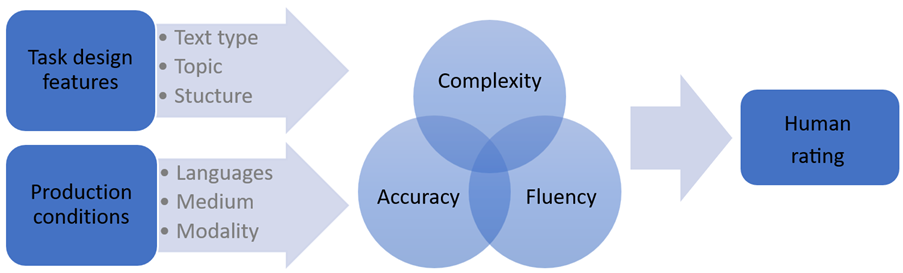
Auf der Grundlage von Grangers (2015) Contrastive Interlanguage Analysis ermöglicht das SWIKO-Korpus eine Vielzahl interessanter Forschungsfragen unter Berücksichtigung von
Merkmalen der Aufgabengestaltung (Textart, Themenvertrautheit, Struktur) und Produktionsbedingungen (Sprachen, Modus, Modalität);
linguistischen Eigenschaften der resultierenden Produktionen (z. B. basierend auf dem CAF-Rahmenwerk von Bulté et al. 2012: Complexity, Accuracy and Fluency);
GER Einstufungen
Beispiele sind im Abschnitt «Publikationen» zu finden.
